- HOME
- Multi-armed bandit testing: what it is, when it works, and when it doesn't
Multi-armed bandit testing: what it is, when it works, and when it doesn't
- Last Updated : June 17, 2026
- 66 Views
- 16 Min Read
1. What is multi-armed bandit testing?
Here's something nobody mentions when they talk about A/B testing: running one is expensive. Not in money,but in conversions. The moment you start a test, you're committing to send a chunk of your traffic to a page that might turn out to be worse. And you have to keep doing that, in equal measure, until you hit your sample size. Even if it's obvious by day three that one version is losing.
Multi-armed bandit testing was built around that specific frustration. Instead of holding a rigid split for the full duration, it shifts traffic toward whichever variant is performing better — while the test is still running. You still learn. You just don't pay as much for the learning.
The trade-off is real, though. MAB gives up some statistical certainty in exchange for fewer wasted conversions. That's not a flaw — it's a design choice. And knowing when that trade-off is worth making is most of what this guide is about.
Where does the name come from?
The name comes from an old probability problem. Slot machines are called one-armed bandits — one lever, and a habit of taking your money. The multi-armed version is the problem of choosing between several machines with unknown payouts: how do you maximize your winnings without knowing which machine is best? That's the same question MAB testing applies to your variants. Which one is performing best, and how quickly can you direct more traffic toward it, without abandoning the others before you're sure?
2. How multi-armed bandit testing works
What happens from the moment you launch
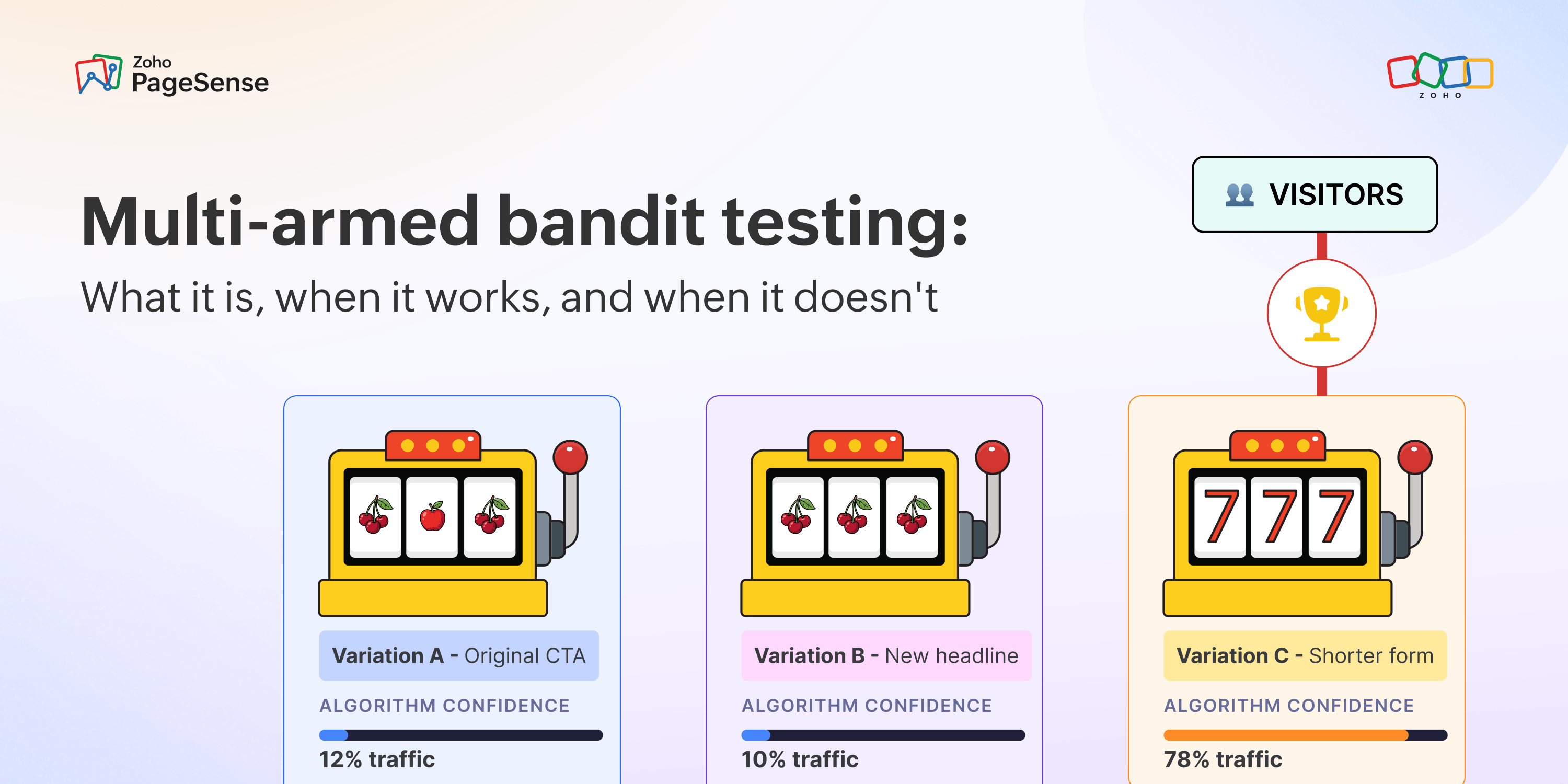
Day one: the algorithm knows nothing. So it splits traffic evenly across all your variants — just as an A/B test would — and starts watching. Every click, every form submission, every conversion (or lack of one) is a data point.
As data accumulates, the algorithm starts to form a picture of which variant is performing better. And it starts acting on it. The better a variant does, the more traffic it gets. There's no finish line. The algorithm doesn't stop when it hits a certain sample size. It keeps adjusting, keeps learning, for as long as you let it run.
Thompson sampling: how the algorithm decides
Most MAB testing tools — including Zoho PageSense — use an algorithm called Thompson Sampling to make traffic allocation decisions. Here's what that means in plain terms.
Each variant carries a running confidence score. Think of it as the algorithm's best current guess at how well that variant converts. At the start, these scores are vague — every variant could be anywhere from 2% to 20% conversion. The algorithm doesn't know yet.
With every visitor, that picture gets sharper. A variant that keeps converting well develops a score weighted toward higher rates. One that keeps underperforming gets pushed the other way. The algorithm then routes the next visitor to whichever variant looks strongest at that moment — but still sends the occasional visitor to weaker variants, just in case.
That 'just in case' is deliberate. Early leaders don't always hold. A variant that looks strong on Tuesday morning might be getting lucky with a particular audience. The algorithm hedges, keeps a little exploration running, and only really commits when the evidence is overwhelming.
Let's understand this with an example. Imagine you're testing three CTA button colors — blue, green, and orange. On day one, traffic is split roughly equally. By day three, green is showing a stronger conversion rate. The algorithm starts routing 50% of traffic to green, 30% to blue, 20% to orange. By day seven, green is getting 75% of the traffic, but blue and orange are still receiving visitors. If orange suddenly starts performing better (maybe weekend traffic behaves differently), the algorithm will notice and adjust.
What the algorithm is not doing:
It's worth being clear about a few things MAB doesn't do, because they're commonly misunderstood.
It doesn't react instantly. Meaningful reallocation takes time. On a low-traffic site, the split might barely budge for days. The algorithm needs data before it can act on data.
It doesn't juggle multiple goals. There's one primary metric. That's all it uses to allocate traffic. Everything else is visible in your reports, but it doesn't influence the algorithm at all.
It doesn't produce statistical significance. A MAB winner is the variant that maximized conversions during the test — not the variant that's been statistically proven to be better. Those aren't the same thing. If you need to walk into a board meeting and defend your result with a p-value, MAB isn't the right tool.
It doesn't cope well with delayed conversions. Thompson Sampling assumes the conversion happens close to when the visitor sees the variant. If your sales cycle takes a week, the algorithm will be making allocation decisions before it knows how most of those visits actually ended.
3. MAB vs A/B testing: the real trade-offs
The most common way people frame this is 'MAB is faster than A/B.' That's true, but it's not the important part. They're not faster and slower versions of the same thing. They're solving different problems.
A/B testing is built to answer a question — definitively. Did this change make a measurable difference? It holds a fixed split, controls for variables, and at the end gives you a statistically validated result you can build on. MAB is built to maximize conversions while you're still figuring out the answer. It trades statistical rigor for fewer wasted visits during the test.
Three things A/B testing gives you that MAB doesn't
1. Statistical significance
A/B testing produces a result you can quantify, defend, and act on at scale. 'Variant B won at 95% confidence' means something precise. You can take that to leadership. You can use it to justify a major product decision. A MAB winner means 'this variant got more conversions during the test window.' That's useful — but it's not the same thing, and conflating the two causes real problems downstream.
2. Segment-level analysis
Because A/B tests hold equal traffic across all variants for the full duration, you can cut the data any way you want afterward. Mobile vs desktop. New vs returning. Organic vs paid. Every slice has enough data to be meaningful. In an MAB test, weaker variants receive so little traffic toward the end that slicing their data becomes unreliable. You know which variant won, you just can't dig into why.
3. Multiple goal tracking
Standard A/B tests track as many metrics as you want, with equal reliability across all of them. MAB tracks everything too — but only optimizes for one. The algorithm doesn't care if a secondary metric is quietly deteriorating. It's watching one thing. This matters more than people expect, and Section 5 goes into it in depth.
Comparison table:
Standard A/B test | Multi-Armed Bandit |
Fixed 50/50 (or equal N-way) split held for the full test duration. | Starts with an even split, then dynamically shifts traffic toward stronger variants. |
Produces statistical significance — a p-value and confidence interval. | Does not produce statistical significance. Reports improvement over equal allocation. |
Supports segment-level analysis across all variants. | Limited segment analysis for underperforming variants due to low traffic. |
Tracks multiple success metrics equally. | Optimizes for a single primary metric only. |
Accumulates more data on all variants, including weaker ones. | Rapidly reduces exposure to weaker variants. |
Better for major, hard-to-reverse decisions. | Better for time-sensitive campaigns and ongoing optimization. |
The fastest path to statistical significance. | The faster path to cumulative conversions during the test. |
4. When to use MAB and when not to
When MAB is the right call
1. You have a deadline and can't wait for statistical significance
A SaaS company running a webinar registration campaign. The webinar is in eight days. They have three landing page variants — different headline angles, different social proof placements. A standard A/B test won't reach significance before registration closes. MAB routes more traffic to whichever variant is pulling sign-ups while the window is still open. By day five, one variant is getting 70% of traffic. The team doesn't have a statistically validated winner — but they have more registrations than an equal split would have produced, and the campaign is still live.
2. You're testing something that runs indefinitely
A B2B software company whose pricing page has three different ways of framing the same plan structure — feature-led, outcome-led, and comparison-led. There's no urgency to declare a winner. The page exists permanently, traffic is consistent, and the goal is just to keep improving the trial sign-up rate over time. MAB runs continuously, adjusting as the audience mix shifts. Six months in, what converts best has shifted twice. The algorithm followed.
3. You're running more than two variants, and exposure to losers is costly
An online education platform launching a new course. Four ways of framing the value proposition; outcome-led, audience-led, urgency-led and social proof-led. Fixed split means 25% of traffic to each. Within 72 hours, two variants are clearly underperforming. In a standard test, they keep getting their 25% until the test ends. That's half the campaign traffic continuing to flow to obvious losers. MAB starts pulling away from those variants early. By the end of the window, the stronger framings have captured the majority of visitors, not a quarter each.
4. Your traffic is expensive, and every visitor counts
A financial services company running Google Ads on a loan application page. Cost per click is $25. Three variants — different trust signals, form lengths, headline approaches. At $25 a visitor, every click sent to the weakest variant is a measurable loss. MAB starts reducing that exposure within days. At that CPC, the difference between a fixed split and an adaptive one isn't theoretical — it's a number on a spreadsheet.
5. You have enough traffic for the algorithm to act on
A recruitment agency's job listing page might see 200 visitors a week. A SaaS product's pricing page might see 20,000. The algorithm's ability to reallocate meaningfully within a week looks completely different in each case. If your page isn't generating at least a few hundred visitors a day, the split may not shift noticeably within a typical campaign window — and the advantage of MAB over a fixed split diminishes accordingly.
When A/B testing is the better choice
1. The decision is major and hard to reverse
An HR software company is moving from feature-based to seat-based pricing. Every customer, every sales conversation, every piece of marketing is affected. They want to test how it lands before committing. MAB won't give them what they need here — they need statistical confidence across different customer segments, not just a variant that pulled ahead. Equal exposure, segment analysis, and a defensible result. That's an A/B test.
2. You need to understand why, not just what
A subscription service ran an MAB test on its sign-up page. Variant C won clearly — 78% of traffic by the end. They rolled it out. Three months later, the churn in that cohort was higher than usual. The variant converted better but attracted a slightly different type of user. Less engaged downstream. The MAB test couldn't see that. It was watching one metric. An A/B test with equal exposure and a longer analysis window would have let them look at 30-day retention by variant before making the call. If the insight you need goes beyond the conversion event, use an A/B test.
3. You're tracking multiple goals that matter equally
Covered in detail in Section 5. Short version: MAB optimizes for one metric. If you care about two — say, conversion rate and average order value — and there's a real trade-off between them, MAB will optimize the wrong one, and you won't know until it's too late.
4. Traffic is too low for meaningful reallocation
See Section 7. On low-traffic pages, the MAB split may barely shift within your campaign window. Both methods are slow at low traffic — but MAB's specific advantage of acting on early signals is the first thing to disappear.
A simple decision framework
Before choosing between MAB and A/B testing, run through these questions:
Question | If | Method |
Do you have a fixed deadline? | Yes | Consider MAB |
Do you need a statistically validated result? | Yes | Use A/B |
Are you optimizing for a single, clear metric? | Yes | Consider MAB |
Are you making a hard-to-reverse decision? | Yes | Use A/B |
Do you have multiple goals of equal importance? | Yes | Use A/B |
Do you want continuous, ongoing optimization? | Yes | Consider MAB |
5. How to choose your primary metric
Why does this matter more in MAB than in A/B testing
In a standard A/B test, the primary metric determines when the test ends. But because all variants receive equal traffic throughout, you can analyze secondary metrics with roughly the same confidence afterward. You're not locked in.
In an MAB test, the primary metric is the only thing driving traffic allocation. The algorithm watches it, acts on it, and routes traffic based on it — exclusively. Secondary metrics are reported, but they don't factor into anything. This makes metric selection a much more consequential decision. Pick the wrong one and the algorithm will optimize hard in the wrong direction. By the time you notice, your underperforming variants will have received so little traffic that diagnosing what went wrong is nearly impossible.
There's also a practical constraint that catches teams out: you cannot change your primary metric once an MAB test is running. The algorithm has been building its confidence scores based on that metric from the start. Changing it mid-test invalidates the model.
What makes a good primary metric
It happens quickly after the visit.
Thompson Sampling works best when the conversion event follows closely after the user sees the variant. A click, a form submission, an add-to-cart — these are good MAB metrics. A purchase that completes three days later isn't. A subscription renewal in six months definitely isn't. The algorithm makes allocation decisions before those events register, which means it's flying blind.
It directly reflects what you actually care about.
If you're running a promotional campaign, your metric should be purchase completions — not clicks on the promotional banner. Clicks are a proxy. Optimizing for a proxy moves the proxy. The actual goal can stay flat or get worse, and your dashboard will still show a win.
It's clean and unambiguous.
'User engagement' is not a metric. 'Clicked the primary CTA' is. The metric needs to be something the platform can record with certainty — a clear binary or countable event. Vague metrics produce vague results.
The trap: picking a metric that hides a real problem
This is the mistake we see most often. The metric looks right on the surface, but it masks what's actually happening downstream.
You're testing two versions of a pricing page. Variant A generates more free trial sign-ups. Variant B generates fewer sign-ups but converts from trial to paid at a much higher rate. You set 'free trial sign-ups' as your MAB metric. The algorithm routes most traffic to Variant A. You report a win. But if Variant B's trial-to-paid rate is high enough, Variant B was actually generating more revenue — and you optimized away from it.
If there's any meaningful trade-off between two metrics you care about — volume vs quality, clicks vs revenue, sign-ups vs retention — don't use MAB. Run an A/B test instead, where you can analyze both metrics with equal confidence.
6. How to set up and run an MAB test
Choosing what to test
MAB works well for contained, surface-level changes where the impact will show up quickly in a single metric. Things like:
CTA button copy, colour, or placement
Headline variants on a landing page or product page
Hero images or promotional banners
Form length or field order
Offer framing — '30% off' vs 'Save $15'
It's less suited for:
Full page redesigns — too many variables, and it's hard to attribute results to any single change.
Structural UX changes, such as navigation or checkout flow redesigns, warrant a statistically validated A/B test.
Anything where you'll need segment-level analysis to interpret the result
How many variants
There's no hard limit, but more variants mean more dilution early on. Each additional variant slows down how quickly the algorithm can form confident estimates. Two to five variants is a practical range for most sites. Beyond that, you'll need meaningfully higher traffic to see useful reallocation within a reasonable timeframe.
If you genuinely have ten headline variants and want to run them all, MAB actually handles this better than a fixed-split test would, because it stops wasting traffic on obvious underperformers earlier. But be realistic about whether your traffic can support it.
Reading your results
MAB results don't look like A/B results. There's no p-value, no confidence interval, no "winner declared at 95% confidence." What you'll see is simpler: how traffic is currently being distributed, what conversion rate each variant is sitting at right now, and how much better the leader is doing compared to what an equal split would have produced.
When one variant is receiving 80% or more of the traffic, that's the algorithm saying it's confident. Not statistically confident — operationally confident. Those aren't the same thing, and that distinction matters a lot depending on what you're planning to do next.
You've got three reasonable options at that point. You can leave it running — especially on evergreen pages where there's no particular reason to stop. You can call it, roll out the winner to 100%, and move on. Just be honest with yourself that you're making an operational call, not a validated one. Or if the result is going to inform something significant — a pricing decision, a product direction — run a clean A/B test on the top two performers before acting on it at scale. The MAB got you to a strong candidate faster. The A/B test confirms it properly.
At Zoho PageSense, we've seen teams treat an 80% traffic allocation as equivalent to 95% confidence in an A/B test. It isn't. The numbers can look similar. The meaning is different.
7. Common mistakes
1. Treating the MAB winner as statistically validated
This is the one that causes the most downstream damage. A variant that wins an MAB test received more traffic because it performed better on your primary metric during the test window. That's not the same as a statistically validated result. There's no p-value, no confidence interval, and no guarantee that the same variant would win in a controlled experiment.
It matters when the decision downstream is significant. If your MAB winner is going into a strategy review, informing a pricing change, or being used to justify a product roadmap decision, follow it up with an A/B test first. The extra time is worth it.
2. Running MAB when conversion rates aren't stable
Thompson Sampling assumes conversion rates are broadly consistent over the course of the test. In practice, they often aren't. They shift with the day of the week, time of day, traffic source, and external events.
If you start a MAB test on a Monday and Variant B performs strongly on weekdays, the algorithm may start routing most traffic to it by Thursday, before it's seen how either variant performs over a weekend, when a different audience mix arrives. The result is a biased allocation based on an incomplete picture.
If you're running a test across a significant temporal boundary — a weekday-to-weekend shift, a big marketing push, the start of a sale period — be aware that the algorithm's early confidence might be misplaced. More traffic means it adapts faster. Lower traffic, give it more time.
3. Changing a variant mid-test
If you modify a variant after a MAB test has started, the algorithm has to start over. Everything it built — its confidence scores for that variant, its allocation model — was based on the original version. Change the variant, and that data is invalid.What makes this particularly messy is the interpretation problem. If Variant B changed on day five, any data after that point reflects a different Variant B. You've effectively merged two separate experiments into one set of results, with no clean way to separate them.
4. Ignoring secondary metrics
The algorithm optimizes for your primary metric. It doesn't monitor anything else. A variant driving strong primary metric performance might simultaneously be increasing returns, generating more support tickets, or quietly reducing retention. The algorithm won't flag any of that.
Make it a habit to review secondary metrics throughout the test — not just at the end. By the time the test finishes, you may not have enough data on underperforming variants to diagnose a secondary metric problem retrospectively.
5. Expecting MAB to fix a low-traffic problem
MAB reduces the cost of running a test — specifically, the conversion cost of sending traffic to a losing variant. What it doesn't do is reduce the amount of traffic you need to reach a reliable conclusion. It just allocates that traffic more efficiently.
On a page with 200 visitors a week, the algorithm may not shift the split meaningfully for weeks. Both MAB and A/B testing require patience at low volumes. The difference is that MAB won't lock you into a rigid 50/50 split — but don't expect fast reallocation when data is thin.
At Zoho PageSense, low-traffic MAB tests are something we see regularly. The split doesn't shift. The team assumes something is broken. Usually, nothing is broken — there just isn't enough data yet.
8. Frequently asked questions
1. What is multi-armed bandit testing?
It's an experiment method that shifts traffic toward better-performing variants while the test is running, rather than locking in a fixed split until the end. Dynamic traffic allocation is another name for the same thing. The short version: you stop sending equal traffic to a losing page before the test is over.
2. What's the difference between MAB and A/B testing?
The goal is different, which is what most people miss. A/B testing is trying to produce a statistically validated answer — something you can defend, present to stakeholders, and act on for a major decision. MAB is trying to maximize conversions while the test is still going. One optimizes for certainty. The other optimizes for performance during the test. They're not the same thing dressed up differently.
3. Does MAB testing work for low-traffic sites?
Honestly, less than people expect. The algorithm needs data to act on. If your page isn't generating enough of it quickly enough, the split may barely shift within your campaign window — and the main advantage of MAB, that it acts on early signals, just doesn't materialize. Both MAB and A/B testing are slow at low volumes.
4. What is Thompson Sampling?
It's the algorithm PageSense uses to decide where to send each visitor. Each variant builds up a confidence score based on how it's been converting. Wide and uncertain early on, so the algorithm keeps traffic spread out. As conversions come in and scores sharpen, more traffic follows the strongest performer. No manual input needed at any point.
5. Can I still see raw data for every variant?
Yes, always. The traffic shifts, the data doesn't hide. Impressions, clicks, conversions — all of it stays visible for every variant in real time, for the full duration of the test.
6. How long does a MAB test run?
There's no fixed endpoint, which is one of the things that makes it different from a standard A/B test. It runs until you stop it, or until a variant is so dominant you're satisfied. For a campaign, it ends when the campaign does. For an evergreen page — a homepage headline, a persistent CTA — some teams just leave it running indefinitely. The algorithm keeps adjusting as behavior changes. That's kind of the point.
7. What type of A/B testing is being compared here?
The classic frequentist kind. Fixed split, predetermined sample size, p-value at the end. That's what most people picture when they say 'A/B test.' It's also what MAB is most commonly compared against. Worth knowing: PageSense also supports Bayesian A/B testing, which works differently — it updates results as data comes in rather than waiting for a predetermined endpoint. All three methods are in the same dashboard.
8. Can MAB handle more than two variants?
Yes. It maintains separate confidence scores for each variant and allocates across all of them at once. Two to five variants is the practical range for most sites — beyond that, you'll need significantly higher traffic for the algorithm to form confident estimates in a reasonable timeframe.
