סוכני AI: הצורך בתשתית דאטה


מאמר ראשון בסדרה בת ארבעה חלקים בנושא תשתית דאטה לסוכני AI (Agentic Data Infrastructure).
היום כל אפליקציה עסקית מגיעה עם סוכן AI משלה. כל אחד מהם טוב בעבודה שלו. הבעיה היא שאף אחד מהם לא מדבר עם השני. סוכן ה-helpdesk שלכם לא יודע על חשבוניות שלא שולמו בזמן, וסוכן ה-CRM שלכם לא תמיד מודע לקריאות שירות דחופות שנותרו פתוחות. כל סוכן רואה רק חלק מהפעילות העסקית ומתייחס אליו כאל התמונה המלאה. כשסוכנים עובדים עם דאטה חלקי, הם נותנים תשובות חלקיות - וככל שמטמיעים יותר סוכנים, הפער הזה רק הולך וגדל.
בעיית הגישה הישירה
רוב הסוכנים מתחברים ישירות ל-API של האפליקציה, מושכים דאטה ומנתחים אותו. זה אמנם פתרון שמהיר ליישם בהתחלה, אבל ככל שהפעילות של העסק מתרחבת להיקפים גדולים, השיטה הזו מייצרת חמש בעיות ידועות מראש.
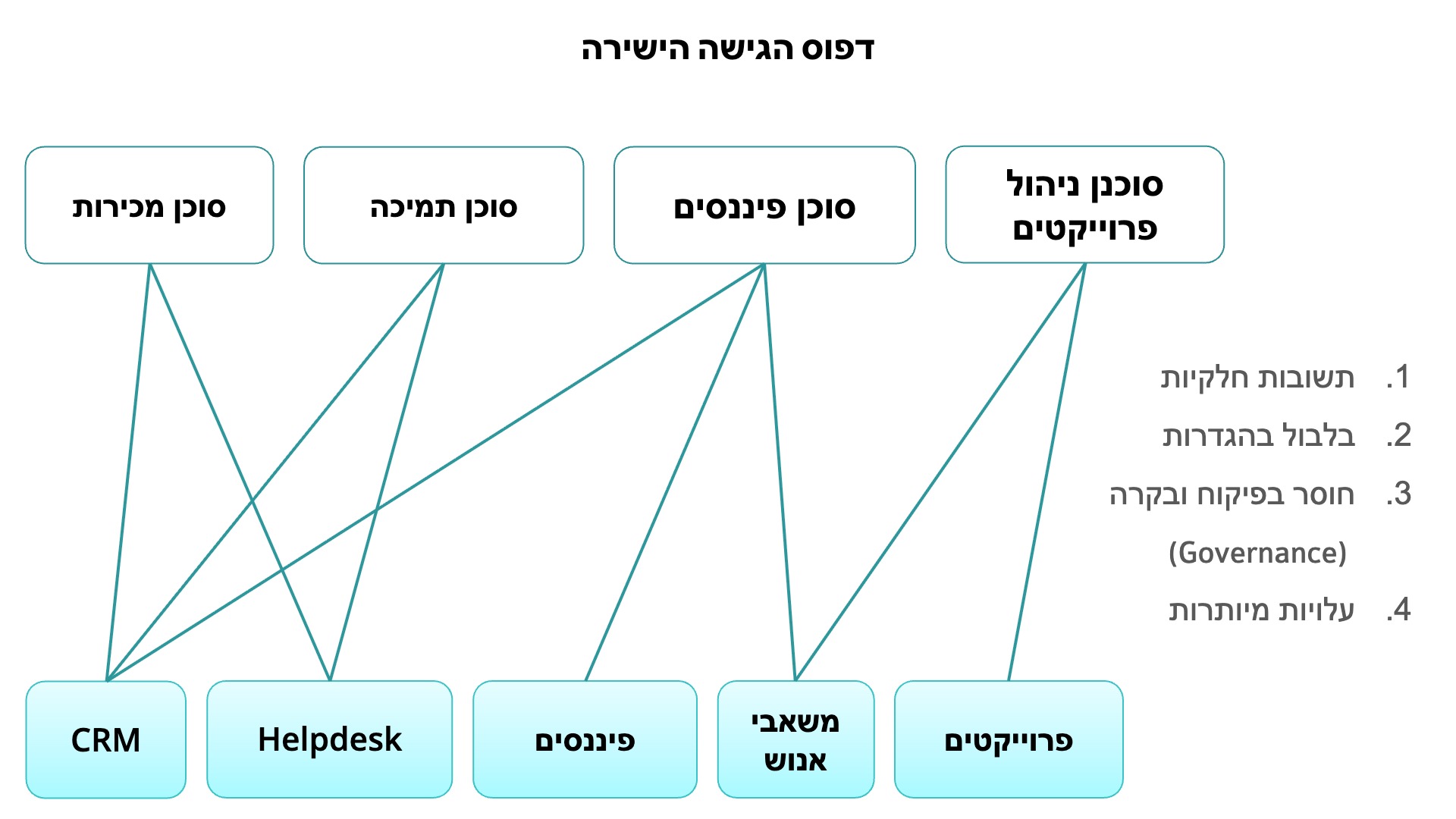
1. נתונים מפוזרים (Data fragmentation)
בחברת Mid-market ממוצעת, הדאטה מפוזר בין עשרות אפליקציות שונות: CRM, מערכת קריאות שירות (helpdesk), פיננסים, משאבי אנוש, ניהול פרויקטים, ניהול מלאי ועוד. כשסוכן יכול לראות דאטה רק מאפליקציה אחת, התשובות שלו ישקפו רק את השטח המצומצם הזה.
לדוגמה, כשמנהל מכירות שואל סוכן: "על אילו לקוחות כדאי לי לשים דגש ברבעון הזה?", הסוכן יבדוק את גודל העסקה ואת השלב שלה ב-CRM. אבל הוא לא יידע שלשלושה מהלקוחות האלו יש קריאות שירות דחופות שפתוחות כרגע, לארבעה יש חשבוניות שלא שולמו ולקוח אחד בדיוק ביטל מנוי למוצר אחר של החברה. התשובה שהסוכן ייתן לא תהיה שגויה, אבל יהיו חסרים בה פרטים קריטיים.
2. בלבול בהגדרות (Semantic confusion)
כששואלים "מה ההכנסה החודשית שלנו?", התשובה תלויה במערכת שאתם שואלים. ה-CRM שלכם סופר עסקאות שנחתמו, בזמן שתוכנת הנהלת החשבונות סופרת הכנסה מוכרת. אלו הגדרות שונות שמשרתות מטרות שונות. כשסוכני AI מושכים דאטה ישירות ממערכות המקור, הם מאמצים אוטומטית את ההגדרה הספציפית שבה המערכת הזו משתמשת. המצב הזה, שבו שני סוכנים שונים מציגים מספרי הכנסה שונים, הופך מיד לבעיה של עקביות בנתונים (Data consistency).
3. פערי פיקוח ובקרה (Governance gaps)
כשסוכן מתחבר ל-API של מערכת המקור, הוא משתמש בדרך כלל בחשבון שירות (Service account) בעל גישה רחבה מאוד. אין שום שכבה מרכזית שמפקחת על אילו נתונים הסוכן יכול לראות, מי אישר לו את הגישה, או מה הוא עושה עם המידע הזה.
כשמדובר בסוכן אחד או שניים, זה עדיין בר ניהול. אבל כשיש עשרים סוכנים בצוותים שונים, ולכל אחד מהם יש גישת API ישירה, אתם מייצרים חשיפת אבטחה שקשה מאוד לנטר ולבקר. בדיקה עצמאית של ההגדרות עבור כל סוכן בנפרד גוזלת המון זמן, וזה פשוט לא מעשי ברגע שהארגון גדל.
4. עלויות מצטברות
בכל פעם שסוכן פונה למערכת המקור, הוא מושך דאטה גולמי ומזין אותו לתוך מודל השפה. הטוקנים (Tokens) האלו מצטברים. אם הסוכן צריך להצליב נתונים בין מערכות שונות, הוא מבצע מספר קריאות API ומבזבז טוקנים רק על עיבוד והמרת המידע. אותה רשומת לקוח עשויה להימשך ולהיות מעובדת עשרות פעמים ביום על ידי סוכנים שונים ועלויות ה-LLM שלכם עולות מהר מאוד.
5. רגישות לשינויים
ה-APIs של מערכות המקור משתנים. עדכוני סכמה (Schema), שינוי שמות של שדות ושינויי הרשאות עלולים לפגוע באינטגרציות של הסוכנים ללא כל אזהרה. מכיוון שאין שכבת ניטור בין הסוכן למקור, אף אחד לא ישים לב לבעיה עד שמישהו יקבל תשובה שגויה.
בעיה מוכרת עם שם חדש
מדובר בדיוק באותו סט בעיות שמחסני נתונים (Data Warehousing) פתרו בעבר עבור הפקת דוחות וניתוח נתונים. אי אפשר להריץ דו"חות אמינים ישירות מתוך בסיסי הנתונים של סביבת הפרודקשן. יש צורך במאגר מידע מאוחד, עם הגדרות עקביות וגישה מבוקרת ומפוקחת. עולם סוכני ה-AI נמצא כעת בדיוק באותה פרשת דרכים. המושג שמתגבש כיום בתעשייה נקרא "תשתית דאטה לסוכני AI" (Agentic Data Infrastructure) והוא מוגדר פשוט כשכבת הדאטה שתוכננה במיוחד כדי לשרת סוכנים.
התשתית הזו כוללת:
מאגר דאטה מאוחד לכל האפליקציות בארגון.
שכבה סמנטית (Semantic layer) המציגה הגדרות עסקיות עקביות.
הכנה והמרת דאטה (Data preparation and transformation).
מנגנוני פיקוח ובקרת גישה (Governance).
APIs או פרוטוקולים המאפשרים לסוכנים להריץ שאילתות אמינות.
אם זה נשמע לכם כמו פלטפורמת BI, אתם צודקים
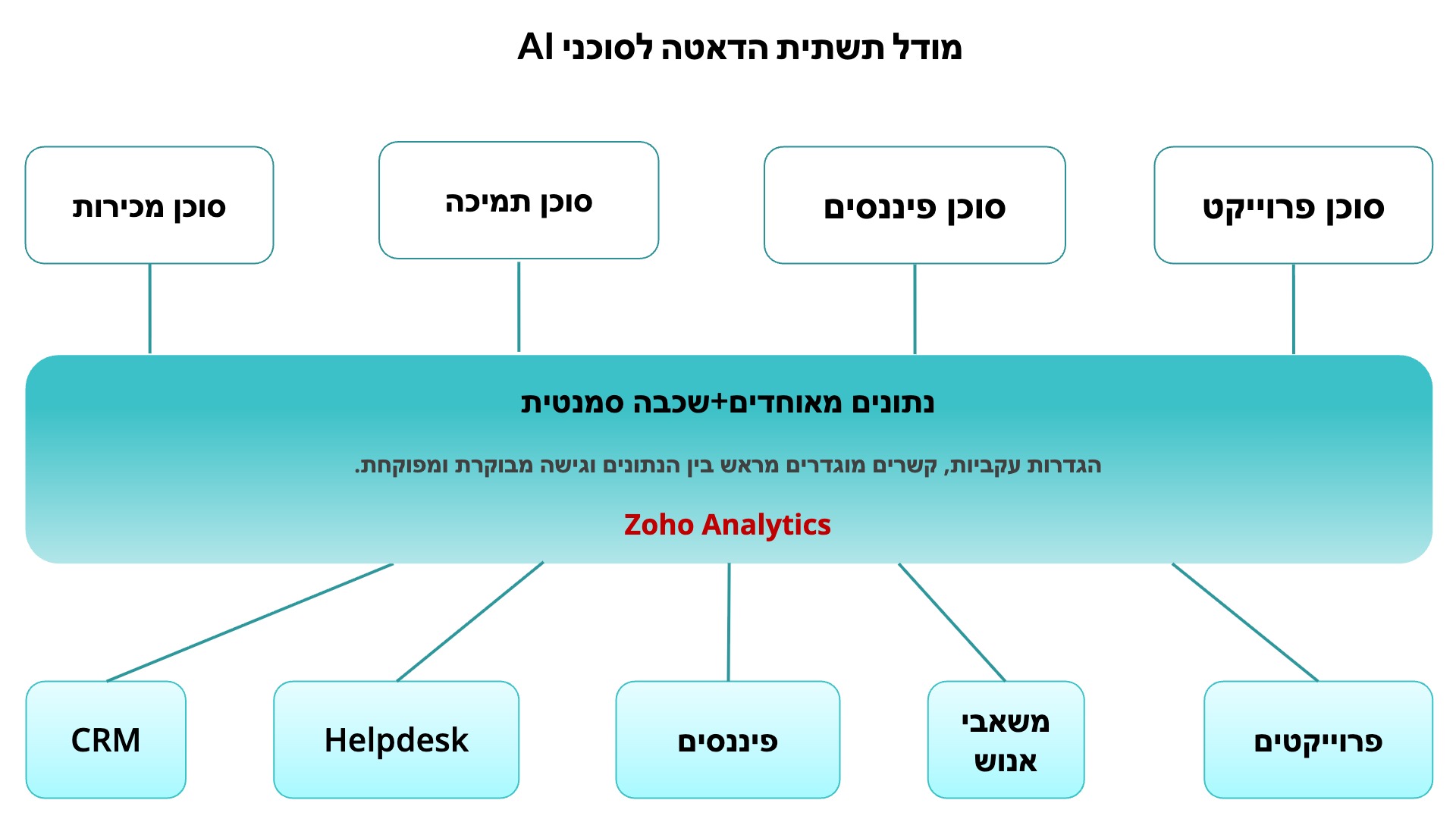
יכול להיות שהתשתית כבר קיימת אצלכם
אם אתם משתמשים ב - Zoho Analytics, כבר בניתם חלק משמעותי ממנה. המערכת מתחברת לאפליקציות שלכם, מאחדת את הדאטה, מגדירה מדדים, מייצרת קשרים מוגדרים מראש בין הנתונים ומחילה מנגנוני בקרת גישה. זו לא סתם פלטפורמת BI, זו הליבה של שכבת דאטה לסוכני AI.
השינוי כאן לא דורש רכישת תשתית חדשה. הוא דורש בעיקר להבין שמה שכבר בניתם עבור ה-BI שלכם יכול לשרת מטרה נוספת - להעניק לסוכני ה-AI תשתית נתונים אמינה, מבוקרת ומוגדרת היטב.
במאמר הבא, נראה מה נתונים מאוחדים ושכבה סמנטית באמת עושים עבור סוכני AI, ולמה המודל הזה מייצר תוצאות טובות בהרבה מאשר גישה ישירה.




Comments