Agentic AI: The need for a data foundation

This is the first post of the 4-part series on Agentic Data Infrastructure.
Every business app now ships with an AI agent. Each one is good at its own job. The problem is, none of them talk to each other. Your helpdesk agent doesn't know about overdue invoices. Your CRM agent may not know about open support escalations. Each agent sees a slice of the business and treats it as the whole picture. When agents work with partial data, they give partial answers. As you add more agents, that gap compounds.

The direct-access problem
Most agents connect directly to an app's API, pull data, and reason over it. This is fast to set up, but at the same time, it leads to five predictable problems at scale.
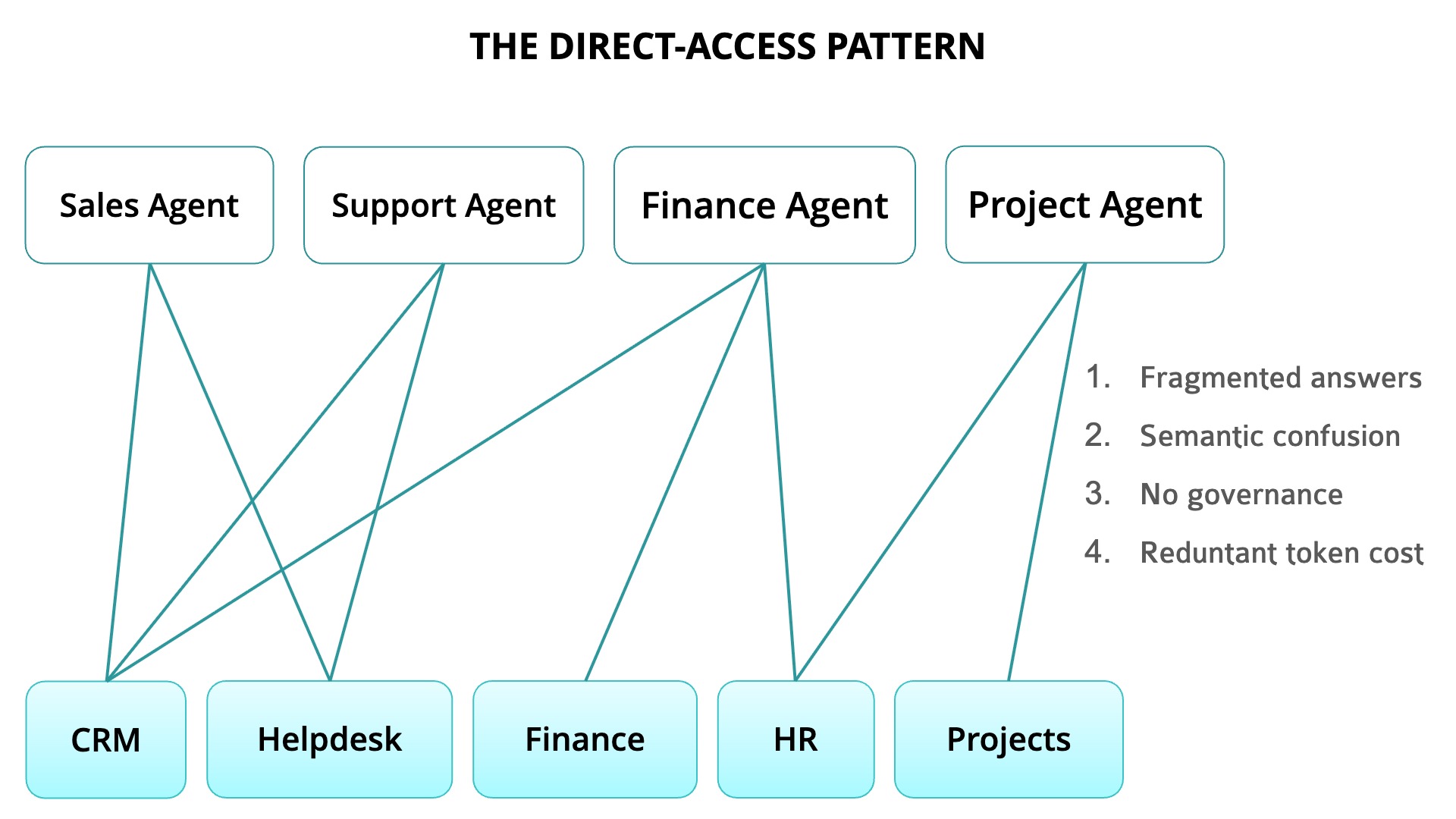
1. Data fragmentation
A typical mid-market company has data spread across a dozen or more applications: CRM, helpdesk, finance, HR, project management, inventory management etc. When an agent can only see one app's data, its answers reflect that limited view.
When a sales manager asks an agent, "Which accounts should I prioritize this quarter?", the agent checks deal size and pipeline stage from the CRM. It may not know that three of those accounts have open support escalations, four have overdue invoices, and one just churned on a related product. The answer it provides may not be wrong, but may be incomplete in ways that matter.
2. Semantic confusion
When "What's our monthly revenue?" is the question, the answer depends on which system you ask. Your CRM counts booked deals, whereas your accounting software counts recognized revenue. These are different definitions serving different purposes. When agents pull data directly from source systems, they inherit whatever definition that system uses. Two agents giving different revenue numbers becomes a data consistency problem.
3. Governance gaps
When an agent connects to a source system's API, it typically uses a service account with broad access. There's no centralized layer controlling what data the agent can see, who authorized it, or what it does with the information.
With one or two agents, this is manageable. With twenty agents across different teams, each with direct API access, you've created a security surface that's hard to audit. Checking every agent's configuration individually is time-consuming and not scalable.
4. Cost accumulation
Every time an agent queries a source system, it pulls raw data and feeds it into a language model. Those tokens add up. If the agent needs to join data across systems, it makes multiple API calls and burns tokens on data transformation. The same customer record might get pulled and processed dozens of times a day by different agents. Your LLM costs add up fast.
5. Brittleness
Source system APIs change. Schema updates, field renames, and permission changes can break agent integrations without warning. Because there's no monitoring layer between the agent and the source, nobody might notice until someone gets a bad answer.
A familiar problem with a new name
This is the same set of problems data warehousing solved for reporting. You can't run reliable reports off production databases directly. You need a consolidated store with consistent definitions and governed access. Agentic AI is at the same crossroads. The concept forming around it is called "agentic data infrastructure". It's defined as the data layer designed to serve agents.
It includes:
- A unified data store across your applications
- A semantic layer with consistent business definitions
- Data preparation and transformation
- Governed access controls
- APIs or protocols for reliable agent queries
If that sounds like a BI platform, it should.
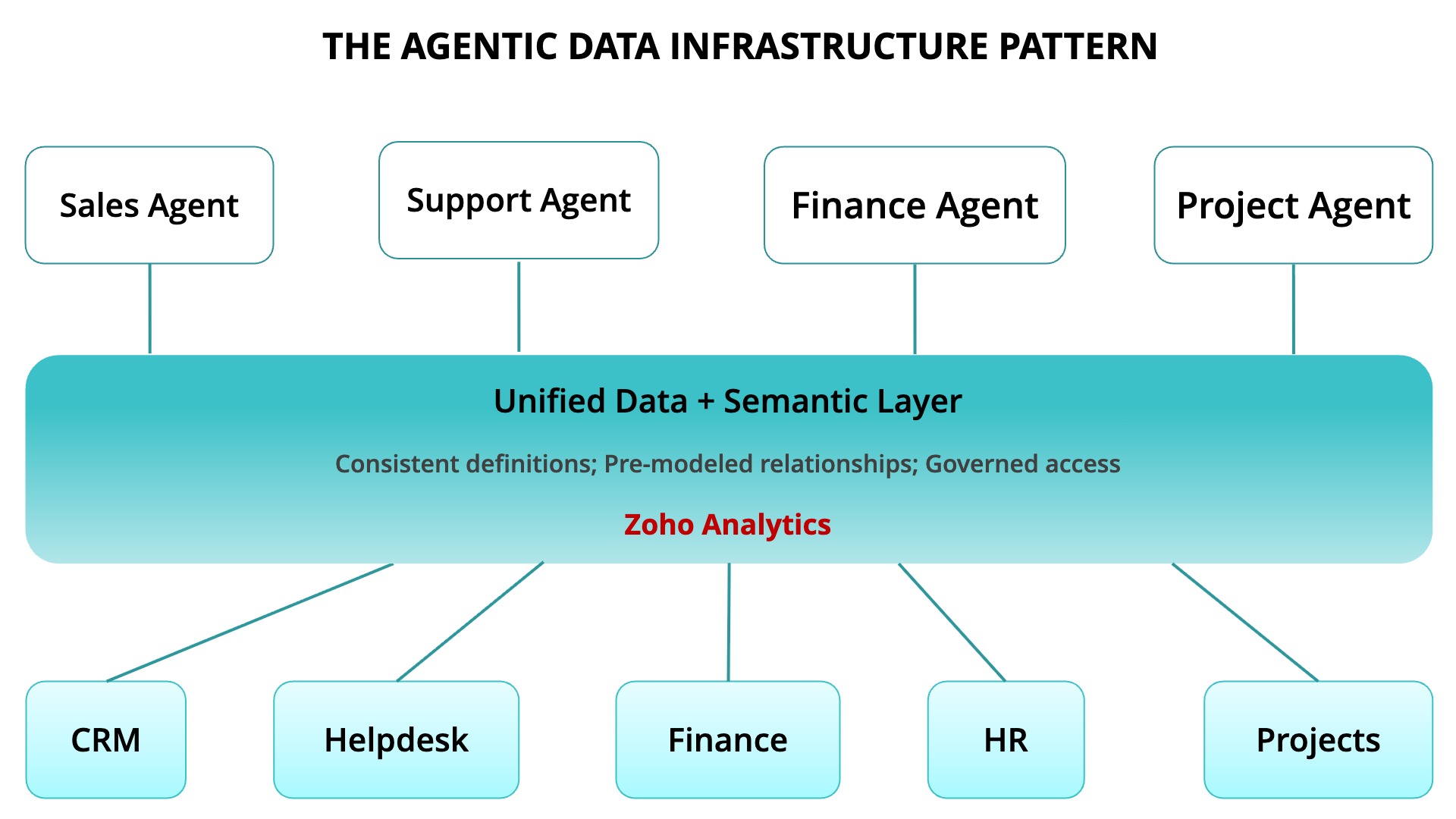
You may already have the foundation
If you're using Zoho Analytics, you've built a significant chunk of this. It connects to your apps, unifies data, defines metrics, models relationships, and applies access controls. That's not just a BI platform. That's the core of an agentic data layer.
The shift isn't buying new infrastructure. It's recognizing that what you've built for business intelligence can serve a second purpose: giving AI agents a reliable, governed, well-defined data foundation.
In the next post, we'll look at what a unified data and semantic layer actually does for agents, and why it produces better results than direct access.




Comments