Wat zal ik leren?
- Wat is ETL?
- Wat zijn de verschillende stappen bij ETL?
- Wat waren de hoofddoelen van vroege ETL-systemen?
- Hoe hebben ETL-systemen zich in de loop der jaren ontwikkeld? Welke invloed heeft cloud computing hierop gehad?
- Wat zijn de voordelen van moderne gegevensbeheersystemen ten opzichte van verouderde op ETL gebaseerde systemen?
- Wat zijn tools voor gegevensvoorbereiding? Hoe verschillen deze van verouderde ETL-tools?
- Wat zijn de voordelen van moderne gegevensbeheersystemen ten opzichte van verouderde ETL-tools?
- Conclusie
Wat is ETL? Een uitgebreid overzicht
ETL, een acroniem voor Extract, Transform, Load, vormt de hoeksteen van het proces waarmee bedrijven inzicht kunnen verwerven in hun enorme gegevenslandschappen. Laten we eens kijken naar wat ETL-tools doen en hoe ze in de loop der jaren zijn geëvolueerd. We zullen ook kort ingaan op wat moderne tools kunnen doen voor gegevensvoorbereiding en hoe ze verouderde ETL-processen verbeteren.
Wat is ETL?
ETL, wat staat voor Extract, Transform, Load, is een gegevensintegratieproces uit het domein van de datawarehousing waarbij gegevens uit verschillende bronnen worden geëxtraheerd, getransformeerd naar een indeling die geschikt is voor analyse en geladen in een centraal archief. Dit enkele, samenhangende archief wordt soms ook wel de 'Enige bron van waarheid' genoemd.
Wat zijn de verschillende stappen bij ETL?
ETL kan worden onderverdeeld in drie verschillende fasen:
- Het extraheren van gegevens uit bronsystemen;
- Het transformeren van de gegevens om in analytische en andere zakelijke behoeften te voorzien;
- Het laden van de gegevens in een gegevensmagazijn of database.
Wat zijn de hoofddoelen van vroege ETL systemen?
ETL werd geïntroduceerd in de jaren 1970, samenvallend met het ontstaan en de groei van datawarehousing. Het werd oorspronkelijk ontworpen voor computationele en analytische vereisten en groeide uit tot de de facto methode voor het verwerken van gegevens voor datawarehousing.
Het doel van het proces was om gegevens uit verschillende bronnen binnen te halen en ze te transformeren zodat ze voldoen aan een standaard schema of gegevensmodel.
ETL deed het voorbereidende werk voor gegevensanalyse en machine learning, waarbij gegevens werden gestroomlijnd door middel van bedrijfsregels ten behoeve van business intelligence en geavanceerde analyses.
Het doel was om zowel de operationele efficiëntie als de gebruikersinteractie te verbeteren door:
- Gegevens op te halen vanuit oudere systemen.
- De kwaliteit en uniformiteit van gegevens te verfijnen.
- Gegevens te integreren in een speciaal aangewezen database.
Deconstructie van het ETL-proces
Hoe hebben ETL-systemen zich in de loop der jaren ontwikkeld? Welke invloed heeft cloud computing hierop gehad?
De architectuur van modern gegevensbeheer verschilt enorm van het gegevensbeheer uit de begindagen van ETL. In het moderne tijdperk van cloud computing, IoT en AI is de hoeveelheid gegevens die door bedrijven wordt vastgelegd enorm toegenomen: bedrijven zijn van miljoenen transacties naar miljarden transacties gegaan. Moderne gegevensbeheersystemen zijn mee geëvolueerd met deze veranderingen.
Vandaag de dag kijken bedrijven niet alleen naar transactiegegevens om beslissingen te nemen, maar identificeren en isoleren ze ook 'signalen' uit de enorme hoeveelheden gegevens. Het gaat niet alleen om het stapsgewijs verbeteren van bedrijfsprocessen, maar ook om het identificeren van nieuwe kansen.
Cloud computing bracht oplossingen zoals gegevensopslag in de cloud met zich mee die kosteneffectieve opslag op schaal boden. Organisaties die voorheen gestructureerde gegevens opsloegen in on-premises gegevensmagazijnen, hebben tegenwoordig verschillende opties voor gegevensopslag, waaronder data lakes en cloud blob-systemen. Deze systemen zijn geschikt voor ongestructureerde gegevens en slaan gegevens vaak op in hun onbewerkte indeling.
Wat zijn de voordelen van moderne gegevensbeheersystemen ten opzichte van verouderde op ETL gebaseerde systemen?
Bij moderne gegevensbeheersystemen staat de behoefte aan meer flexibiliteit, schaalbaarheid en efficiëntie in gegevensverwerking voorop.
Net zoals de vroege ETL-systemen opkwamen naast de systemen voor datawarehousing, zijn moderne datatools nauw verbonden met de opkomst van gegevensopslagsystemen van een nieuwe generatie.
De snelle ontwikkeling van flexibele en schaalbare gegevensopslagsystemen heeft geleid tot het loskoppelen van de verplaatsing van gegevens en de voorbereiding van gegevens. In feite zijn de extractie- en laadaspecten van ETL losgekoppeld van het transformatieaspect van gegevensbeheer.
Laten we dit onderzoeken aan de hand van een voorbeeld uit een moderne context. Laten we eens kijken naar een bedrijf dat op verschillende locaties aanwezig is en veel afdelingen heeft. Elke afdeling of locatie verwerkt zelfstandig de eigen gegevens. De salesgegevens worden opgeslagen in een CRM, de personeelsgegevens worden beheerd in een HR-systeem en de voorraad- en aanverwante gegevens worden bijgehouden in een op maat gemaakt systeem.
Data-engineers op de IT-afdeling voerden ETL-processen uit om gegevens uit deze ongelijksoortige bronnen te halen, te transformeren naar een indeling die ideaal is voor analyse, en in gegevensmagazijnen te laden.
Modern gegevensbeheer vereist echter geen hulp van data-engineers of zelfs een IT-team om gegevens voor te bereiden voor analyse. Zelfs niet-technische personen kunnen gegevens voorbereiden op een manier die zij geschikt achten voor hun analyse en besluitvorming.
Wat zijn tools voor gegevensvoorbereiding? Hoe verschillen deze van verouderde ETL-tools?
Tools voor gegevensvoorbereiding, of 'data wrangling' zoals dit soms wordt genoemd, zijn moderne gegevenstools die het 'transformatie'-gedeelte van de conventionele ETL-cyclus aanpakken. Het is ook het 'content'-gedeelte van het ETL-proces waar gegevens worden voorbereid voor downstream gebruik.
Hoewel ze volgens dezelfde basisprincipes werken als vroege ETL-systemen, zoals het in kaart brengen van schema's tussen relationele databases, het berekenen van formules en het laden van databases, gaan moderne tools voor gegevensvoorbereiding veel verder.
Waar traditionele ETL-tools afhankelijk waren van data-engineers en een IT-afdeling om de processen uit te voeren, stellen moderne tools voor gegevensvoorbereiding een nieuwe set gebruikers in staat om met gegevens te werken. Door een gebruiksvriendelijke interface en visuele uitsplitsingen over gegevenskwaliteit, slimme suggesties en andere visuele aanwijzingen te bieden, stelt gegevensvoorbereiding tegenwoordig zelfs niet-technische gebruikers in staat om gegevens voor te bereiden.
Moderne tools voor gegevensvoorbereiding democratiseren het proces van gegevenstransformatie door het proces van gegevensvoorbereiding via visuele aanwijzingen open te stellen voor niet-technische gebruikers.
Self-servicetools voor gegevensvoorbereiding maken gebruik van visualisatie en door AI gestuurde aanbevelingen om het proces van gegevensvoorbereiding open te stellen voor een nieuwe generatie gebruikers, waaronder datafanaten.
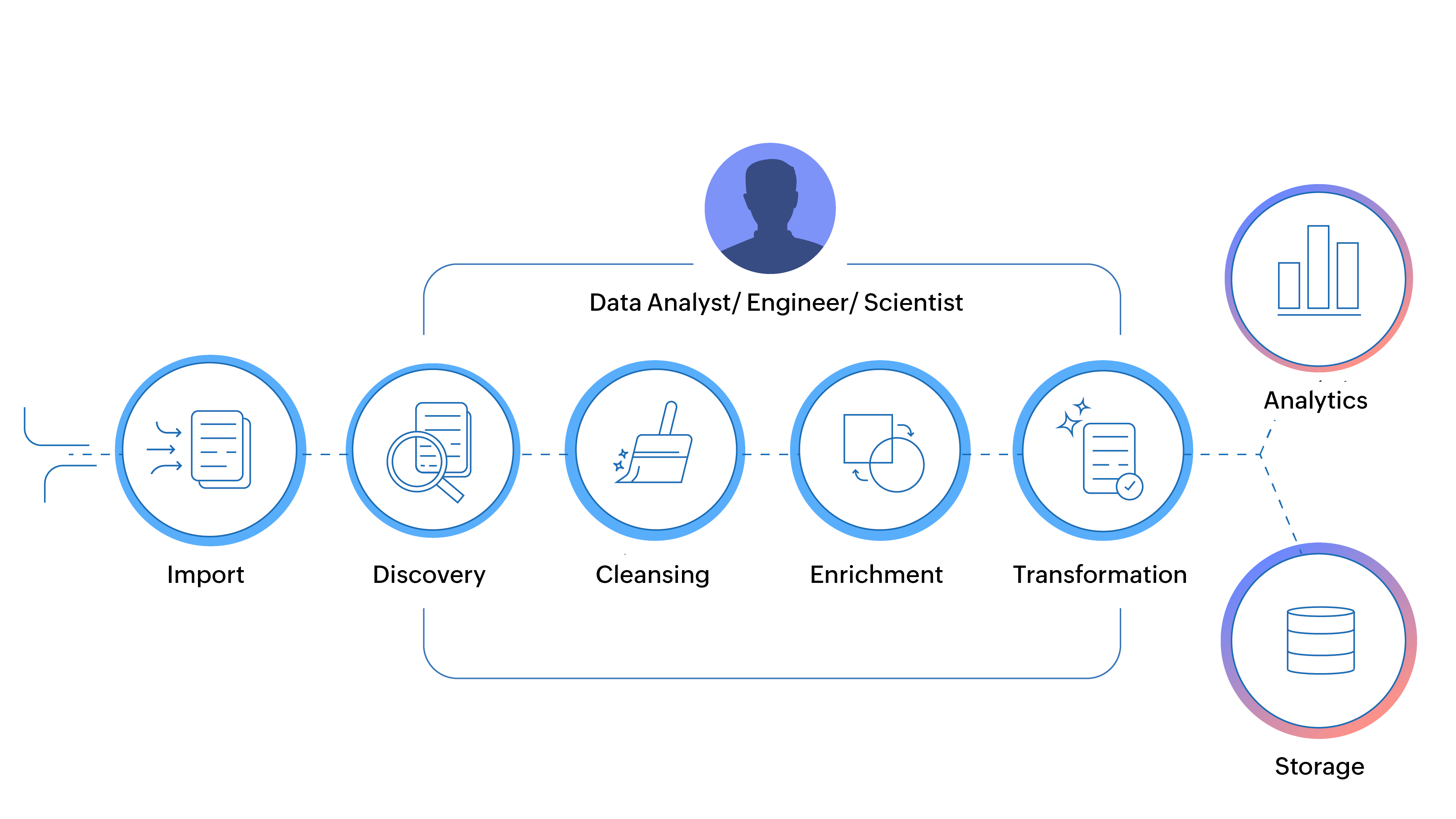
Met moderne tools voor gegevensvoorbereiding kunnen gebruikers gegevens voorbereiden in een gebruiksvriendelijke interface en gebruikmaken van moderne technologieën zoals kunstmatige intelligentie.
Wat zijn enkele van de belangrijkste voordelen van het gebruik van tools voor gegevensvoorbereiding?
Moderne tools voor gegevensvoorbereiding, die tegenwoordig een van de kritieke onderdelen vormen van de workflow voor gegevensbeheer, bieden drie grote voordelen als het gaat om gegevensbeheer. Snellere time-to-value Verlaging van operationele kosten Verbetering van monitoring en beheer
Conclusie
Oppervlakkig gezien is de stroom van gegevens door een gegevensbeheersysteem vandaag de dag in wezen vergelijkbaar met wat er gebeurde tijdens de beginjaren van ETL-systemen. Tegenwoordig is het voorbereiden van gegevens echter gedemocratiseerd dankzij moderne tools die gebruikers visuele aanwijzingen geven over hoe ze eenvoudig gegevens kunnen voorbereiden.