Que vais-je apprendre ?
- Qu'est-ce que le processus ETL ?
- Quelles sont les différentes étapes du processus ETL ?
- Quels étaient les principaux objectifs des premiers processus ETL ?
- Comment les systèmes ETL ont-ils évolué au fil des années ? Quel a été l'impact du cloud sur ces systèmes ?
- Quels sont les avantages des systèmes de gestion de données modernes par rapport aux systèmes utilisant l'ancien processus ETL ?
- Que sont les outils de préparation des données ? En quoi sont-ils différents des anciens outils ETL ?
- Quels sont les avantages des systèmes de gestion des données modernes par rapport aux anciens outils ETL ?
- Conclusion
Qu'est-ce que le processus ETL ? Explication détaillée
ETL est l'acronyme d'Extract, Transform, Load (extraction, transformation, chargement). Ce terme désigne le processus de base permettant aux entreprises d'exploiter leurs vastes paysages de données. Commençons par examiner les capacités des outils ETL et leur évolution au fil des années. Nous expliquerons également brièvement les capacités des outils de préparation de données et les améliorations qu'ils offrent par rapport aux anciens processus ETL.
Qu'est-ce que le processus ETL ?
Le processus ETL, pour Extract, Transform, Load (extraction, transformation, chargement), est un processus permettant d'intégrer des données stockées dans des domaines d'entreposage, qui consiste à extraire les données de diverses sources de données, à les transformer en un format adapté à l'analyse et à les charger dans un référentiel central. Ce référentiel unique et cohérent est parfois appelé « source unique d'informations ».
Quelles sont les différentes étapes du processus ETL ?
Le processus ETL se décline en trois étapes :
- Extraction des données des systèmes sources
- Transformation des données pour répondre aux besoins analytiques et autres exigences de l'entreprise
- Chargement des données dans un entrepôt de données ou une base de données
Quels étaient les principaux objectifs des premiers processus ETL ?
Le processus ETL est né dans les années 1970, en même temps que l'apparition et le développement de l'entreposage des données. Il a été conçu à l'origine à des fins de calcul et d'analyse et est devenu la méthode de traitement par défaut des données pour l'entreposage de données.
L'objectif du processus était de récupérer des données de différentes sources et de les transformer pour les adapter à un schéma ou un modèle de données standard.
Le processus ETL a jeté les bases des analyses de données et de l'apprentissage automatique, en simplifiant les données avec des règles métier conçues pour faciliter la veille stratégique et les analyses avancées.
Il visait à améliorer l'efficacité opérationnelle et l'interaction avec les utilisateurs en :
- récupérant les données des anciens systèmes ;
- affinant les données afin d'améliorer leur qualité et leur uniformité ;
- intégrant des données dans des bases de données spécialisées.
Déconstruction du processus ETL
Comment les systèmes ETL ont-ils évolué au fil des années ? Quel a été l'impact du cloud sur ces systèmes ?
L'architecture de la gestion des données moderne est bien différente de la gestion des données appliquée durant les premières années des processus ETL L'ère moderne du cloud, de l'IoT et de l'IA a vu la quantité de données enregistrées par les entreprises exploser, passant de millions de transactions à des milliards de transactions. Les systèmes de gestion des données modernes ont évolué avec ces changements.
Aujourd'hui, les entreprises ne se contentent pas de consulter les données transactionnelles pour prendre des décisions, elles identifient et isolent les « signaux » importants parmi ces quantités astronomiques de données. Leur objectif n'est pas seulement d'améliorer les processus métiers, mais également d'identifier de nouvelles opportunités.
Le cloud a apporté des solutions comme le stockage de données dans le cloud, offrant un stockage économique à grande échelle. Les organisations qui stockaient auparavant des données structurées dans des entrepôts de données sur site disposent aujourd'hui de nombreuses options de stockage de données, dont les lacs de données et les systèmes blob dans le cloud. Ces systèmes peuvent recueillir des données non structurées et stockent souvent des données dans leur format brut.
Quels sont les avantages des systèmes de gestion de données modernes par rapport aux systèmes utilisant l'ancien processus ETL ?
Les systèmes de gestion des données modernes visent à garantir un traitement de données plus flexible, plus évolutif et plus efficace.
Tout comme les premiers systèmes ETL qui sont apparus en même temps que les systèmes d'entreposage de données, les outils de données modernes sont étroitement liés à l'émergence des systèmes de stockage de données de dernière génération.
Le développement rapide des systèmes de stockage de données flexibles et évolutifs a entraîné la séparation du transfert des données de la préparation des données. En effet, l'extraction et le chargement du processus ETL ont été dissociés de la transformation de la gestion des données.
Examinons ce point de plus près avec un exemple tiré d'une situation moderne. Prenons l'exemple d'une entreprise disposant de plusieurs sites et services. Chaque service ou site gère ses données séparément. Les données de ventes sont stockées dans un système CRM, les informations sur les employés sont gérées dans le système RH et l'inventaire et les enregistrements associés sont enregistrés dans un système personnalisé.
Les ingénieurs de données du service informatique ont exécuté les processus ETL pour extraire les données de ces différentes sources, les transformer en un format adapté pour l'analyse et les charger dans des entrepôts de données.
Néanmoins, la gestion des données moderne ne nécessite pas l'aide des ingénieurs de données ni même de l'équipe informatique pour préparer les données pour l'analyse. Même les utilisateurs non techniques peuvent préparer les données et les adapter pour l'analyse et la prise de décision.
Que sont les outils de préparation des données ? En quoi sont-ils différents des anciens outils ETL ?
Les outils de préparation des données ou de formatage des données sont des outils de données modernes qui gèrent l'aspect « transformation » du cycle ETL classique. Ils représentent également la partie « contenu » du processus ETL, où les données sont préparées pour être utilisées en aval.
Même s'ils fonctionnent sur les mêmes principes que les premiers systèmes ETL (c'est-à-dire la mise en correspondance des schémas des bases de données relationnelles, le calcul de formules et le chargement des bases de données), les outils de préparation des données vont un peu plus loin.
Alors que les outils ETL traditionnels nécessitent l'aide d'ingénieurs de données et du service informatique pour exécuter les processus, les outils de préparation des données modernes permettent à un nouveau groupe d'utilisateurs de travailler sur ces données. Grâce à une interface conviviale et des représentations visuelles de la qualité des données, des suggestions intelligentes et d'autres informations visuelles, les outils de préparation des données actuels permettent à des utilisateurs non techniques de préparer les données.
Les outils de préparation des données modernes démocratisent le processus de transformation des données en ouvrant le processus des utilisateurs non techniques grâce à des informations visuelles.
Les outils de préparation des données en libre-service utilisent la visualisation et les recommandations de l'IA pour rendre accessible la préparation des données à une nouvelle génération d'utilisateurs, dont les amateurs de données.
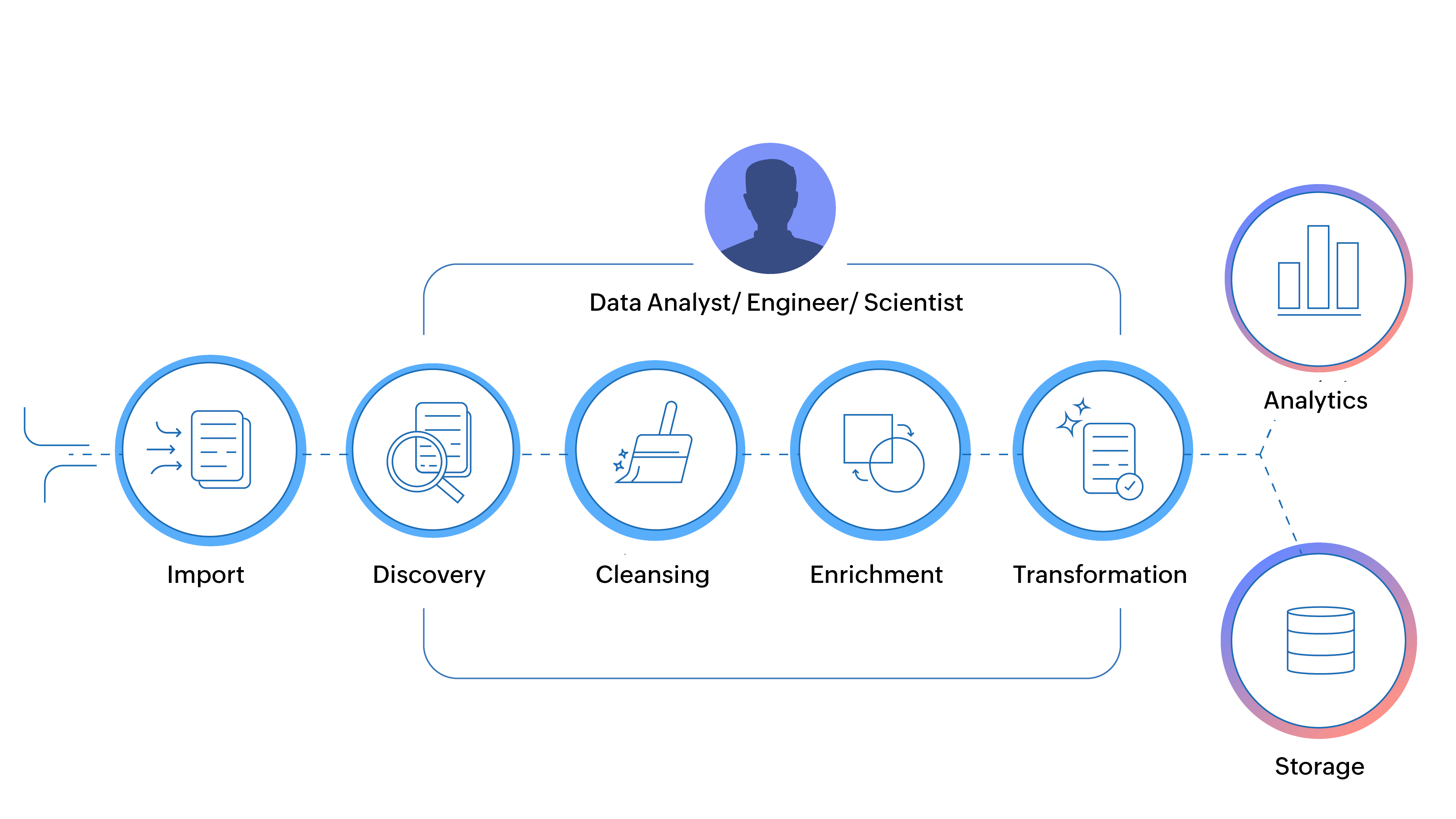
Les outils de préparation des données modernes permettent aux utilisateurs de préparer des données à l'aide d'une interface simple et de tirer parti de technologies modernes comme l'intelligence artificielle.
Quels sont les principaux avantages des outils de préparation des données ?
Les outils de préparation des données, qui représentent aujourd'hui une part essentielle du workflow de gestion des données, offrent trois principaux avantages liés à la gestion des données. Accélération du délai de rentabilisation Réduction des coûts opérationnels Amélioration de la surveillance et de la gouvernance
Conclusion
En surface, le traitement des données par un système de gestion des données moderne conserve l'esprit des premiers systèmes ETL. Cependant, le processus actuel de préparation des données a été démocratisé grâce aux outils modernes qui fournissent aux utilisateurs des informations visuelles pour aider à préparer facilement les données.